
We confront hard, technical challenges every day that have real-world implications for our customers. Our products ensure timely availability of business-critical data, like employee timesheets, payroll, job costs, subcontracts, change orders, and more.
In this post, we’ll explain the key areas where our work pushes the envelope - and why these problems should excite any engineer who enjoys solving puzzles that matter.
What are we building?
As a quick primer, we’re building two core products:
- An API that unifies different systems on a single standard, allowing our software-vendor customers (and us) to read and write data across dozens of systems in a normalized way. This is hard because each system models data in unique ways, the systems are deployed differently (cloud, hosted, on-prem), each system has distinct business logic and validation behavior, and many systems don’t have APIs or documentation.
- A web application for construction companies that keeps data in sync between the core systems that run their business (e.g. project management, accounting). This web app uses our own API to translate and sync data between systems automatically. Syncing data may seem simple on the surface, but there are thousands of nuances that total to a very hard challenge overall.
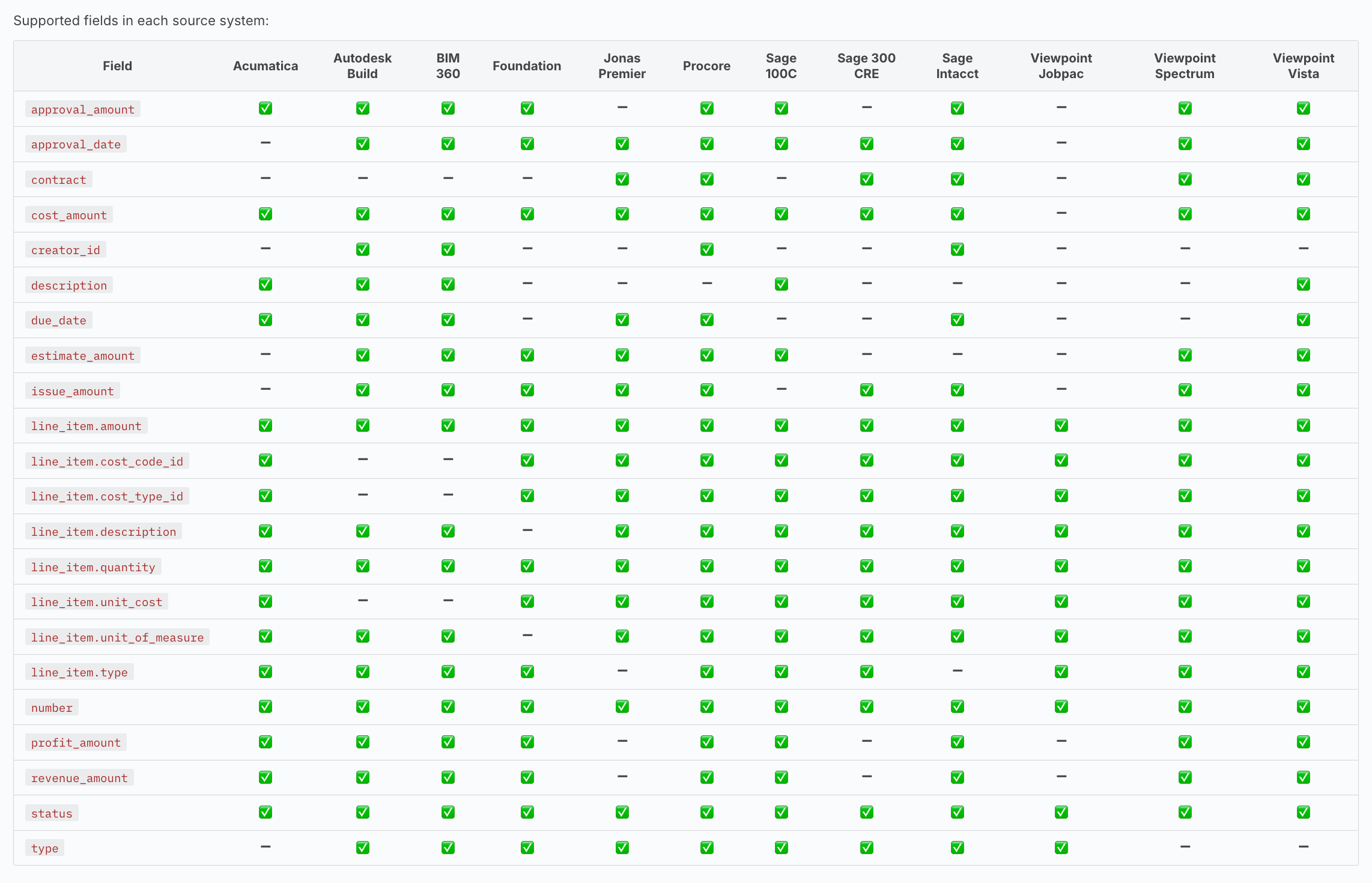
Unifying 30+ fragmented systems
Our API is a unifying data layer that normalizes 35 disparate systems (and counting) into a single, coherent standard. We like to think of it as a universal translation service. To achieve meaningful unification across systems, we have to build standardization at several layers:
- Data Objects & Models: we define a unified data schema that must accommodate a variety of formats. Every new integration forces us to reconcile differing data structures and edge cases, ensuring consistency across the board.
- Authentication & Account Linking: we’ve built a standardized back-end infrastructure and front-end UX for user identity and account linking that works across each system we support. This requires designing an agnostic approach that extends to each new system add, whether it’s cloud, hosted, or on-prem.
- API Features: for features like API filtering and pagination, each integration has its nuances. We research every system’s capabilities and constraints, then implement a generic solution that scales as more systems are added. We avoid building one-off solutions, and invest in a framework that is flexible, performant, and maintainable.

Handling the variety in each integration
Every integration we undertake is unique. It’s a deep dive into that system’s idiosyncrasies — part investigation, part archeology, part translation.
- System-Specific Challenges: each system demands comprehensive research to understand its protocols, data structures, business logic, quirks, and potential pitfalls. Our TPMs lead the charge on research, writing comprehensive, methodical docs explaining the intricacies to our developers and broader team. There’s no one-size-fits-all solution, which is part of the value of our product.
- Novel Solutions: this variety means our engineers are continuously learning and adapting. What works for one system may not work for another, so we’re constantly developing new strategies and tools to manage these differences. Part of our challenge is developing a comprehensive automated test framework that ensuress reliability across our 110 data models.
Connecting to decades-old systems
A significant portion of our work involves interfacing with on-prem systems that were built 20–40 years ago. This introduces several demanding challenges:
- Diverse Technologies: we encounter systems underpinned by SQL, DLLs, and even Pervasive SQL, Each has its own set of protocols and limitations. Our engineers must be versatile, understanding legacy architectures as well as modern software practices, bridging the gap between the two.
- Real-Time Communication: many of these systems lack native support for real-time data exchange, like webhooks. We develop solutions with web-sockets and custom polling mechanisms to simulate real-time interactions, ensuring that our API responses are timely, accurate, and efficient.
- Security and Reliability: converting on-prem systems to behave like cloud-based services means addressing not only performance but also security. Our solutions must ensure that data remains secure during transit and that interactions are logged and auditable.
Here’s an example project you might work on: building webhooks from scratch.
- Problem: data within source systems can update not only as a result of us performing an action, but also as a result of a third party performing an action. When third parties update data, we have no way of knowing this update occurred, because most source systems we connect don’t offer native webhooks.
- Solution: add a webhooks implementation will allow us to subscribe to changes within a source system and react accordingly when third parties trigger updates. For some source systems the subscription will be trivial because these systems provide API endpoints to register a subscription. Most other source systems though do not provide a means for webhook subscription, so we need to build our own solution that sits in front of the source system.
Ensuring operational excellence on top of legacy systems
Building a reliable API layer on older software is a challenge of both architecture and operations:
- API Reliability: many of our source systems were not built with API integration in mind. We have to build a reliable abstraction layer that handles intermittent failures, unexpected data formats, and variable performance, as we scale to tens of millions of API calls per week.
- Testing at Scale: with 1900+ endpoints, our testing frameworks need to be both comprehensive and scalable. We continuously develop new tests to capture edge cases and ensure that any change doesn’t introduce regressions. Our full test suite comprises of over 10,000 handwritten unit tests, thousands of targeted integration tests connecting to external dependencies, and dozens of acceptance tests that validate the full end-to-end user flows.
- Balancing Innovation and Stability: we innovate in expanding our integrations while enforcing strict SLAs. This requires designing systems that are both resilient and adaptable, ensuring that rapid development does not compromise system reliability.
Example project you might work on: optimizing how we cache data.
- Problem: we cache customer data to speed-up API operations by removing the latency from the root source system. Improvements range from 5-100x. We population caches on a fixed cadence, and it’s an all-or-nothing action, meaning we have to fetch all data before we can determine what is actually new or different in order to update the cache.
- Solution: this approach has a number of inefficiencies. For example, if only one model is created/updated, we should only fetch the updated model (instead of all of them) and update our cache accordingly. Or, when a model is created/updated, we should be informed and react as soon as this occurs, so we update data closer to real-time.
Supporting speed and scale, with real-world pressure
We handle tens of millions of API requests weekly. The challenge isn’t just high volume; it’s the need for rapid, iterative development based on direct customer feedback.
- Efficient Data Handling: our systems must store and retrieve large datasets with minimal latency. We design caching layers that not only reduce response times but also adapt dynamically as data volumes grow.
- Rapid Iteration: we ship code daily, and every change is scrutinized by real-world usage. Our engineers work under the discipline of continuous integration and deployment, iterating quickly while ensuring that system performance remains robust.
- Performance Tuning: optimizing for scale means regularly profiling our systems, identifying bottlenecks, and refining both code and infrastructure. This is a continual process of measurement, analysis, and targeted improvement.
Example project you might work on: re-architecting our background jobs.
- Problem: we use background jobs to perform a blend of short and long running operations that can be hourly, daily, weekly, or monthly. As we scale to more customers and more data per customer, we have congestion in our background job pipeline. One specific problem is large customers can hog bandwidth and dramatically inhibit the speed at which other customers complete their background jobs.
- Solution: devise a new architecture for background jobs that promotes a fairer distribution of resources, so large customers cannot inhibit smaller ones. Your solution can combine any of vertical scaling, horizontal scaling, scheduling, and prioritzation. You can also investigate the root cause of congestions, and whether we can optimize in a way that reduces the quantity of data needing to be processed.
Juggling back-end and front-end challenges
Our work isn’t confined to the back-end. Our web app has unique UX challenges for a heavily data-intensive product displaying sensitive financial and employee data:
- Dogfooding Our Own APIs: by using our own API , we’re forced to confront the limitations and inefficiencies in real time. This continuous feedback loop drives rapid improvements and deeper insights into user experience.
- Designing for Both Audiences: we build the low-level API infrastructure and the high-level applications that sit atop it. Working on these two levels requires a careful balance between optimizing for our software vendor API customers and our construction web app customers.
Example project you might work on: improving our Sync front-end.
- Problem: customers of our Sync product have minimal ability to configure settings. Almost all settings need to be configured by our team on the backend. Customers don’t have a ton of insight into what occurs when the product runs, relative to what we can see internally.
- Solution: add improvements that help our customers, including:
- An intuitive interface for configuring granular Sync settings
- Dashboards that show past and future syncs scheduled
- Statistics around success/failure/throughput/etc.
- Analytics around the state of data as it transitions, e.g. from status = “Open” to “Approved”
Staying sharp
At Agave, these challenges aren’t abstract ideas - they’re the day-to-day problems that keep our engineering team sharp. If you thrive on solving complex, tangible problems and enjoy working in an environment where every integration is a new puzzle, you’ll find that our work is as rewarding as it is challenging.